设备告警日志分析及处理 网络技术服务的核心实践
在网络技术服务领域,设备告警日志是系统健康状况的“脉搏”与“病历”。高效、精准地分析与处理这些日志,是保障网络稳定、可靠、安全运行的关键。本文将系统阐述设备告警日志分析的流程、核心技术与处理策略。
一、告警日志的价值与内容解析
设备告警日志是由网络设备(如路由器、交换机、防火墙、服务器等)在运行过程中,对异常事件、性能阈值越界、配置变更或安全威胁等状况自动生成的记录。每条告警通常包含时间戳、设备标识、告警级别(如紧急、严重、警告、提示)、告警类型(如链路中断、CPU过载、内存耗尽、安全攻击)以及具体的描述信息。这些日志是故障诊断、性能优化、安全审计和容量规划的第一手资料。
二、告警日志分析的核心流程
- 集中采集与标准化:利用Syslog、SNMP Trap、NetFlow或专用代理等工具,将分散在各设备上的日志实时收集到统一的日志管理平台(如ELK Stack、Splunk、Graylog)。标准化处理(解析、分类、归一化)是后续有效分析的基础。
- 实时监控与过滤:建立实时监控仪表盘,对涌入的告警进行初步筛选。通过设置阈值和过滤规则,抑制重复告警、瞬断告警等“噪音”,聚焦于真正需要关注的事件,避免告警风暴。
- 关联分析与根因定位:这是分析的核心。采用规则引擎或机器学习算法,将不同设备、不同时间产生的相关告警进行关联(例如,同一链路两端的端口同时产生“Down”告警),快速定位故障的根本原因,而非仅仅呈现表面现象。
- 影响评估与优先级排序:根据告警级别、影响的业务范围(用户数、关键应用)以及SLA要求,对告警进行影响评估和优先级排序,确保服务团队能够按照“先重后轻”的顺序高效处理。
三、关键处理策略与自动化响应
- 分级响应机制:建立与告警级别相匹配的响应流程。紧急/严重告警触发自动通知(电话、短信)并升级至高级工程师;警告类告警可纳入工单系统按流程处理;提示类信息则用于趋势分析。
- 知识库与自动化脚本:将历史处理经验沉淀为知识库,为常见告警提供标准处理步骤。对于可预见的、重复性的故障(如服务进程重启、配置回滚),可以开发自动化脚本或通过与运维编排工具(如Ansible、Rundeck)集成,实现告警的自动修复,大幅提升MTTR(平均修复时间)。
- 趋势分析与预防性维护:通过对历史告警日志的长期挖掘,识别周期性模式、性能基线漂移或潜在隐患。例如,某设备内存使用率呈缓慢上升趋势并频繁触发警告,可提前安排扩容或优化,变被动响应为主动预防。
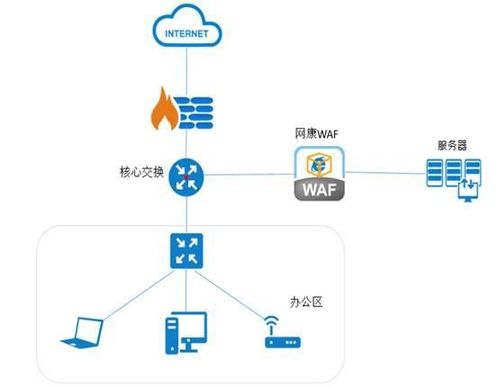
- 安全事件联动:将安全设备(如IPS、WAF)的告警与网络设备日志关联分析,可以更完整地还原攻击路径,实现网络安全事件的快速检测与响应。
四、最佳实践与挑战
- 实践:建立清晰的告警管理策略(定义哪些需要告警);保持日志环境的整洁与归档;定期回顾并优化告警规则;加强团队在日志分析工具使用和网络原理方面的培训。
- 挑战:海量日志带来的存储与处理压力;复杂网络环境下告警关联的准确性;避免自动化误操作带来的二次故障。
在数字化转型深入发展的今天,设备告警日志已从简单的故障记录,演变为驱动网络智能化运维的重要数据资产。通过构建系统化的分析流程、善用自动化工具并秉持主动预防的理念,网络技术服务团队能够将告警从“救火队”的指令,转变为保障业务连续性与提升服务质量的强大引擎。
如若转载,请注明出处:http://www.766853.com/product/43.html
更新时间:2026-05-30 08:22:55